I have released a small Windows desktop app called Promplet.
Promplet is a tray-resident Windows prompt palette for quickly pasting reusable text into AI chats, CLI tools, terminals, Slack, email, and other text inputs.
I often reuse small prompts and text snippets when working with AI chat tools, command-line AI tools, terminals, Slack, email, and other text inputs.
Of course, I could keep those snippets in a text file, a note app, or a clipboard manager. But I wanted something a little more direct:
a small palette that stays on screen
buttons that paste text immediately
groups for organizing prompts
keyboard shortcuts for visible buttons
a simple local app, not a cloud service
That is the idea behind Promplet.
What Promplet Does
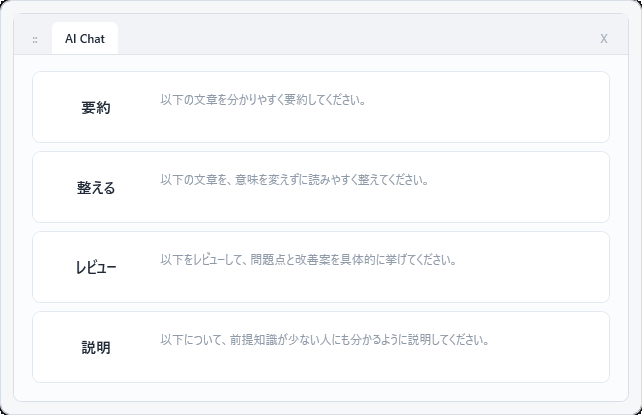
Promplet keeps a small, always-on-top palette on your desktop. Each button represents one reusable prompt or text snippet. Clicking a button pastes the text into the application that had focus before the palette was clicked.
Promplet main palette
The main palette is designed to stay out of the way:
it does not appear in the taskbar
the X button hides the palette instead of exiting the app
the tray icon menu is used for settings, Prompt Library, reload, and exit
only one Promplet instance can run at a time
The palette shows prompts in the selected group. Groups are displayed as tabs, and the prompt buttons are stacked vertically. The palette height automatically follows the number of visible prompt buttons, and the width can be resized from the left or right edge.
Right-clicking a prompt button copies the text without pasting it.
Prompt Library
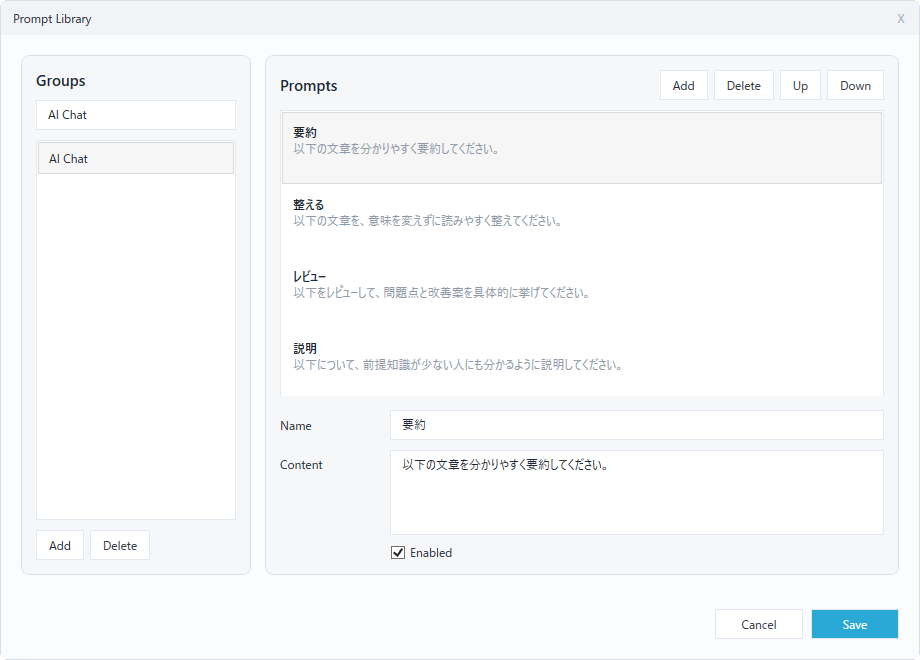
Promplet includes a Prompt Library window for managing groups and prompt buttons.
Promplet Prompt Library
The Prompt Library supports:
adding and deleting groups
renaming groups
adding and deleting prompts
renaming prompts
editing prompt text
enabling or disabling prompts
moving prompts up or down
saving or canceling changes
Promplet supports up to 10 groups. Each group supports up to 10 prompt buttons. This matches the default keyboard shortcuts from Ctrl+NumPad1 through Ctrl+NumPad0.
Settings
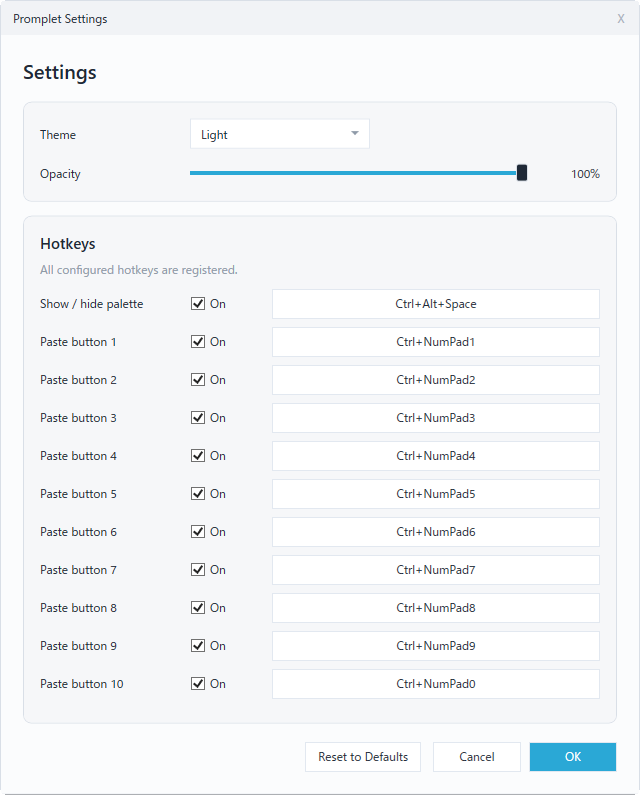
Promplet also has a Settings window.
Promplet Settings
Settings currently supports:
theme mode: System, Light, or Dark
palette opacity
show/hide palette hotkey
paste button hotkeys
reset to defaults
Theme and opacity changes are previewed while the dialog is open.
Default Hotkeys
The default hotkeys are:
Ctrl+Alt+Space: show or hide the palette
Ctrl+NumPad1 ... Ctrl+NumPad9: paste visible buttons 1-9
Ctrl+NumPad0: paste visible button 10
The NumPad shortcuts depend on how Windows reports the physical numpad key, so NumLock should be kept on. Avoid adding Shift to numpad shortcuts because Windows may stop reporting the key as NumPad.
Hotkeys can be changed in Settings.
Install
There is no installer for the current release.
Download the release zip, extract it, and run Promplet.exe.
Open the latest release page.
Download Promplet-v1.0.0-win-x64.zip from the release assets.
Promplet v1.0 is already usable, but I plan to improve it gradually.
Current roadmap direction:
v1.1: data safety, backups, import, export, and restore
v1.2: Windows startup behavior and operational shortcuts
v1.3: diagnostics, logging, and troubleshooting support
v1.4: Prompt Library usability improvements
The roadmap is directional and may change as Promplet evolves.
License
Promplet is licensed under the Apache License, Version 2.0.
Closing Thoughts
Promplet is not intended to be a large prompt management service. It is a small local Windows tool for people who want to keep frequently used prompts and text snippets close at hand.
I made it because I wanted a simple, fast, always-available prompt palette for my own workflow. If you use AI chat tools, AI CLI tools, terminals, Slack, or email every day, it may be useful for you too.
2026年4月23日(木) 17:51 Alex Example <alex@example.com>:
SmartRe for Gmailでは、これを次のような読みやすい形式に書き換えます。
---------- Original message ---------
From: Alex Example <alex@example.com>
Date: Apr 26, 2026, 10:15
Subject: Project update for review
To: User Example <you@example.com>
When you reply in Gmail, the quoted original message and Gmail’s one-line reply header can sometimes feel a little hard to read.
The left quote line, extra spacing, and Gmail-style header are useful, but they may not be ideal if you are used to Outlook-style reply formatting or cleaner business email replies.
That is why I built SmartRe for Gmail™, a Chrome extension that formats quoted reply content and original-message headers in Gmail reply drafts.
SmartRe for Gmail Screenshot
💡 What SmartRe for Gmail Does
SmartRe for Gmail automatically formats quoted content and original-message headers when you reply in Gmail.
It focuses on two things.
1. Clean up quoted content
Gmail replies usually include the original message as quoted content, with a visible left quote line and extra spacing.
SmartRe for Gmail keeps the quote structure intact as much as possible, but adjusts the visual style to make the reply easier to read.
In rich text replies, it removes the visible left quote line and extra spacing.
In Gmail plain text mode, it removes leading quote markers from quoted lines.
The goal is not to break Gmail’s quote structure, but to make the quoted section look cleaner.
2. Rewrite the reply header in an Outlook-style format
Gmail normally inserts a one-line reply header like this:
Apr 26, 2026, 10:15 Alex Example <alex@example.com>:
SmartRe for Gmail can rewrite it into a more readable multi-line format:
---------- Original message ---------
From: Alex Example <alex@example.com>
Date: Apr 26, 2026, 10:15
Subject: Project update for review
To: User Example <you@example.com>
If you are used to Outlook or other desktop email clients, this format may feel more familiar and easier to scan.
💭 Why I Created It
I have previously built a Thunderbird add-on for reply formatting and a Chrome extension called SmartURLs.
But when using Gmail, I still found myself wanting cleaner reply formatting.
Gmail’s conversation view already keeps the message thread, so the quoted original message does not always need to stand out so strongly.
In business email, it can also be helpful to show the original message information — sender, date, subject, and recipient — in a structured multi-line format.
So I decided to build a small Chrome extension focused only on Gmail reply formatting.
What I wanted was:
✨ Automatic formatting when replying
📩 Quote structure preserved as much as possible
📧 Readable Outlook-style original-message headers
🛡️ Local processing inside the browser
🌐 Open-source implementation
🎨 Simple Settings
SmartRe for Gmail keeps its settings simple.
There are currently two options:
Adjust quote style
Rewrite reply header
Both can be turned on or off from the popup.
The extension automatically opens Gmail’s hidden quoted content when you reply, then formats the generated reply content.
⚙️ Key Features
Clean quoted content in Gmail replies
Remove the visible left quote line and extra spacing in rich text replies
Remove leading quote markers in Gmail plain text reply mode
Rewrite Gmail’s one-line reply header into an Outlook-style format
Add sender, date, subject, and To lines when they can be detected
Save settings with Chrome Storage Sync
English and Japanese support
Open source under the Apache License 2.0
🔒 Privacy
SmartRe for Gmail runs on the Gmail reply page.
All formatting is performed inside your browser.
The extension does not send Gmail message contents, profile email addresses, account display names, extension settings, or any other user data to the developer’s servers or to third-party services.
The signed-in Chrome profile email address is used only to add the To line when rewriting the reply header.
本記事の解決策には、主に Windows 11 Pro で利用可能な「ローカル グループポリシー エディター(gpedit.msc)」を使用します。
Windows 11 Home では通常 gpedit.msc(グループポリシー) を使えないため、この記事と同じ GUI 手順はそのままでは再現しにくいと思います。筆者は Home では未検証です。 レジストリを直接編集することで対応できる可能性はありますが、筆者の環境では検証できていないため、Home版での実施は推奨しません。Pro版へのアップグレードを検討するか、警告を受け入れて運用することをお勧めします。